
Czym jest Zasada Odwrócenia Zależności?
Zasada odwracania zależności, w skrócie, mówi:
- Moduły wysokiego poziomu nie powinny zależeć od modułów niskiego poziomu. Oba powinny zależeć od abstrakcji.
- Abstrakcje nie powinny zależeć od szczegółów. To szczegóły powinny zależeć od abstrakcji.
Oznacza to, że zamiast wiązać na sztywno komponenty, które realizują logikę biznesową (wysoki poziom), z komponentami, które zajmują się np. dostępem do danych czy plików (niski poziom), wprowadzamy między nimi warstwę abstrakcji (najczęściej w postaci interfejsu). Kierunek zależności zostaje “odwrócony” – zamiast wysokiego poziomu zależącego od niskiego, oba zaczynają zależeć od wspólnego kontraktu.
Kluczowe Aspekty DIP
- Zależność od abstrakcji: To złota zasada. Zarówno klasy wysokopoziomowe, jak i niskopoziomowe komunikują się poprzez interfejsy, a nie konkretne implementacje.
- Odwrócenie kierunku zależności: Tradycyjnie:
LogikaBiznesowa -> DostępDoPlików. Po zastosowaniu DIP:LogikaBiznesowa -> IInterfejs <- DostępDoPlików. - Wstrzykiwanie zależności (Dependency Injection): To najpopularniejszy mechanizm realizacji DIP. Zamiast tworzyć swoje zależności wewnątrz, klasa otrzymuje je z zewnątrz (np. przez konstruktor). To promuje luźne sprzężenie (loose coupling).
- Korzyści: Łatwiejsze testowanie (możemy wstrzyknąć “zaślepkę”, czyli mocka, zamiast prawdziwej zależności), większa elastyczność (łatwa wymiana implementacji) i pełna zgodność z zasadą Otwate/Zamknięte (OCP).
Przykład Naruszenia Zasady (Sztywne Powiązania)
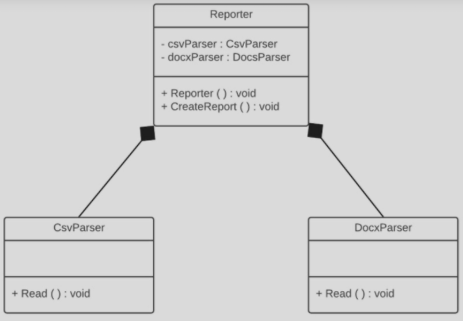
Wyobraźmy sobie klasę Reporter_bad, której zadaniem jest generowanie raportu na podstawie danych z różnych źródeł (np. plików CSV lub DOCX).
Diagram UML
Kod Naruszający Zasadę
W tej wersji Reporter_bad tworzy instancje parserów (CsvParser_bad, DocsParser_bad) bezpośrednio w swoim konstruktorze.
public class Reporter_bad {
private CsvParser_bad csvParser;
private DocsParser_bad docxParser;
// Zależności są tworzone wewnątrz klasy!
public Reporter_bad() {
this.csvParser = new CsvParser_bad();
this.docxParser = new DocsParser_bad();
}
public void createRaport(ReportType reportType) {
switch (reportType) {
case csv:
this.csvParser.read();
break;
case docs:
this.docxParser.read();
break;
default:
break;
}
}
}
// CsvParser_bad i DocsParser_bad to proste klasy z metodą read()Problem z Naruszeniem DIP
Ten kod jest bardzo sztywny i trudny w utrzymaniu.
- Bezpośrednia zależność: Klasa wysokiego poziomu (
Reporter_bad) jest ściśle powiązana z konkretnymi klasami niskiego poziomu (CsvParser_bad,DocsParser_bad). Słowo kluczoweneww konstruktorze to sygnał alarmowy. - Trudności w testowaniu: Jak przetestować
Reporter_badw izolacji, bez faktycznego tworzenia plików CSV i DOCX? Jest to bardzo trudne, ponieważ nie możemy łatwo podmienić prawdziwych parserów na ich testowe odpowiedniki (mocki). - Naruszenie OCP: Co jeśli chcemy dodać obsługę raportów z plików PDF? Musimy zmodyfikować klasę
Reporter_bad, dodając nową zależność i kolejnycasew instrukcjiswitch. To jawne złamanie zasady Otwate/Zamknięte.
Poprawne Zastosowanie Zasady (Elastyczność przez Abstrakcję)
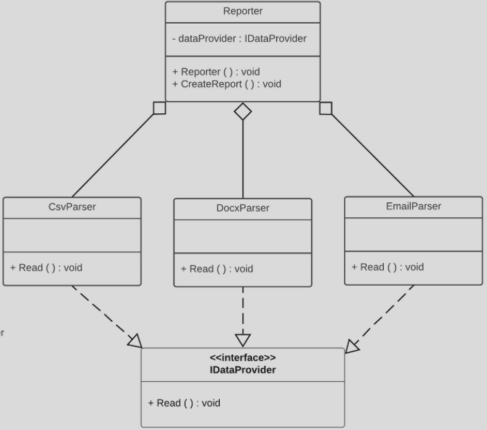
Aby naprawić nasz projekt, wprowadzamy abstrakcję – interfejs IDataProvider, który będzie kontraktem dla wszystkich parserów.
Diagram UML
Poprawiony Kod
Tworzymy interfejs (naszą abstrakcję):
public interface IDataProvider {
void read();
}Klasy niskiego poziomu implementują interfejs:
public class CsvParser implements IDataProvider {
public void read() {
System.out.println("Reading data from CSV file...");
}
}
public class DocsParser implements IDataProvider {
public void read() {
System.out.println("Reading data from DOCX file...");
}
}Klasa wysokiego poziomu zależy od abstrakcji, a zależność jest wstrzykiwana:
public class Reporter {
private IDataProvider dataReader;
// Zależność jest przekazywana z zewnątrz! (Dependency Injection)
public Reporter(IDataProvider dataReader) {
this.dataReader = dataReader;
}
public void createRaport() {
// Reporter nie wie, z jakiego źródła czyta dane. Działa na abstrakcji.
this.dataReader.read();
}
}Kompozycja obiektów odbywa się na zewnątrz (np. w metodzie main):
public class Main {
public static void main(String[] args) {
// Tworzymy konkretną implementację...
IDataProvider csvParser = new CsvParser();
// ...i wstrzykujemy ją do reportera.
Reporter reporter = new Reporter(csvParser);
reporter.createRaport(); // Wyświetli "Reading data from CSV file..."
}
}Teraz to zewnętrzny kod (w tym przypadku klasa Main) decyduje, której konkretnej implementacji parsera użyje klasa Reporter. Odwróciliśmy kontrolę!
Porównanie Przykładów
| Aspekt | Wersja Naruszająca DIP | Wersja Zgodna z DIP |
| Zależność | Reporter_bad zależy bezpośrednio od konkretnych klas CsvParser_bad i DocsParser_bad. | Reporter zależy od abstrakcji IDataProvider. |
| Tworzenie obiektów | Obiekty zależności są tworzone wewnątrz klasy (new). | Zależności są tworzone na zewnątrz i wstrzykiwane (np. przez konstruktor). |
| Elastyczność | Niska. Dodanie nowego parsera wymaga modyfikacji klasy Reporter_bad. | Wysoka. Możemy stworzyć PdfParser implementujący IDataProvider i wstrzyknąć go do Reporter bez żadnych zmian w tej klasie. |
| Testowalność | Trudna. Nie można łatwo podmienić zależności na mocki. | Łatwa. W teście można wstrzyknąć fałszywą implementację IDataProvider. |
Podsumowanie
Zasada Odwrócenia Zależności jest kluczem do tworzenia elastycznych, modułowych i łatwo testowalnych architektur. Promuje ona projektowanie w oparciu o kontrakty (interfejsy), co redukuje sztywne powiązania między komponentami systemu. Kod napisany z naruszeniem DIP jest kruchy i trudny w utrzymaniu, podczas gdy kod zgodny z DIP jest skalowalny i gotowy na zmiany. Stosowanie tej zasady, często poprzez mechanizm wstrzykiwania zależności, to jeden z najważniejszych kroków w kierunku dojrzałej i profesjonalnej architektury oprogramowania.
Bibliografia
- Martin, R. C. (2003). Agile Software Development, Principles, Patterns, and Practices. Prentice Hall.
- Martin, R. C. (2017). Clean Architecture: A Craftsman’s Guide to Software Structure and Design. Prentice Hall.
- Martin, R. C. (2008). Clean Code: A Handbook of Agile Software Craftsmanship. Prentice Hall.